Keypoints as an Object-Centric Interface for Imitation Learning:
Design Choices, Failure Modes, and Real-World Results
Thomas Lips1, Marco Moletta2, Michael C. Welle2,3, Danica Kragic2, Francis wyffels1
1AI and Robotics Lab, IDLAB-AIRO, Ghent University-imec
2Robotics, Perception and Learning Lab (RPL), EECS, KTH Royal Institute of Technology
3INCAR Robotics AB, Stockholm, Sweden
Abstract ▼
RGB-based imitation learning requires many demonstrations to generalize to unseen objects or scenes, motivating research into intermediate representations to improve generalization for robotic manipulation. Visual foundation models enable one-shot extraction of keypoints to provide such representation. However, it remains unclear how to integrate them into imitation learning optimally and when they outperform alternative representations. We combine approaches from previous works on keypoint imitation learning (KIL) and investigate several design choices to provide practical guidelines. Using over 2000 real-world rollouts, we also assess the generalization capabilities of KIL to unseen objects and scene variations. KIL achieves a 75% overall success rate across five tasks, significantly outperforming the RGB baseline (47%) and performing on par with S2-Diffusion (73%). Finally, we explore the limitations of the foundation models used for keypoint extraction and extend KIL to tasks with multiple object instances. Our results confirm KIL as a data-efficient approach for robot learning, though it does not outperform alternative representations and inherits limitations of the foundation models used for keypoint extraction.
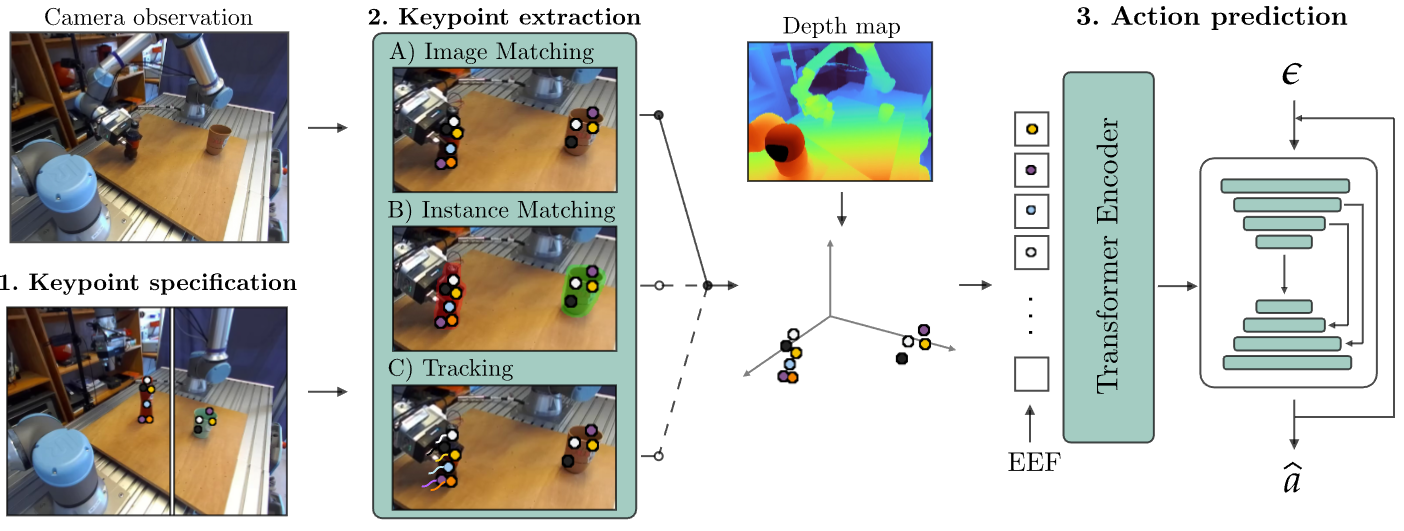


Tasks & Evaluation
We evaluate KIL across five real-world manipulation tasks on two robot platforms. For each task, 50 demonstrations are collected with two training objects. Object positions are varied across the workspace; orientations are limited to ±30° around a canonical orientation. Each method is evaluated with 30 rollouts across three conditions: in-distribution, novel objects, and scene variations.
Pick a randomly placed shoe by the heel and put it on a tray at a fixed location. Success requires correct placement without moving the tray and with the shoe oriented within 90° of the tray’s y-axis.



Pick a randomly placed, upright mug by the rim and place it on a tray at a fixed position.



Pick a plastic bottle, move it over a cup at a randomized position, and tilt it as if pouring. Both objects are rotationally symmetric so orientation does not matter. Success requires the bottle to be tilted beyond horizontal and held directly above the cup.



Pick up a randomly placed pen and drop it into a cardboard box at a fixed location. Success requires the pen to fall inside or remain on top of the box without being dropped or moving the box.



Grasp a randomly positioned mouse from the sides and place it on a mouse pad at a fixed location. Success requires the mouse to be placed on the pad facing the scene camera with the scroll wheel visible, without moving the pad or dropping the mouse.



Experiments
We structure our evaluation around five research questions (RQ1–RQ5) using over 2000 real-world rollouts across five manipulation tasks on two robots. Each method is tested using 30 rollouts, split into 10 trials per condition: in-distribution, novel objects, and scene variations. Additionally, we highlight a surprising sensitivity of KIL to object orientations.
RQ1: Does KIL improve generalization over alternative representations? ▼
We compare KIL against an RGB diffusion policy baseline and S²-Diffusion across five tasks and three evaluation conditions. KIL achieves 75% overall success, 28 percentage points above the RGB baseline (47%). S²-Diffusion (73%) performs on par with KIL. RGB collapses to just 10% on scene variations, which explains most of the performance gap.
| Method | In-distribution (%) | Novel objects (%) | Scene variations (%) | Avg. (%) | 95% CI |
|---|---|---|---|---|---|
| RGB | 74% | 56% | 10% | 47% | [38, 55] |
| S²-Diffusion | 80% | 74% | 66% | 73% | [66, 80] |
| KIL (IM) | 88% | 68% | 70% | 75% | [68, 82] |
| KIL (IN) | 76% | 70% | 64% | 70% | [62, 77] |
| KIL (T) | 76% | 74% | 74% | 75% | [67, 81] |
RQ2: How do the three keypoint extraction methods compare? ▼
We compare image matching (IM), instance matching (IN), and tracking (T) for KIL across all five tasks and three conditions. All three methods achieve similar success rates, so adding explicit tracking or first detecting instances does not help on the considered tasks.
| Method | In-distribution (%) | Novel objects (%) | Scene variations (%) | Avg. (%) | 95% CI |
|---|---|---|---|---|---|
| KIL (IM) | 88% | 68% | 70% | 75% | [68, 82] |
| KIL (IN) | 76% | 70% | 64% | 70% | [62, 77] |
| KIL (T) | 76% | 74% | 74% | 75% | [67, 81] |
RQ3: Which visual foundation models are best suited for keypoint extraction? ▼
We compare three feature models: RADIOv2.5-B, DIFT (ensemble sizes 2 and 8) and DINOv3-B. We evaluate them across all keypoint extraction methods, and test on two tasks: Place Shoe and Place Mug. The performance of all foundation models is similar, but RADIOv2.5-B performs best for image matching, while DIFT₂ works best for instance matching and tracking.
| Extraction Method | Feature Model | Place Shoe (/30) | Place Mug (/30) | Avg. (%) | 95% CI |
|---|---|---|---|---|---|
| Image | RADIOv2.5-B | 25 | 26 | 85% | [73, 93] |
| DIFT₂ | 13 | 24 | 62% | [48, 74] | |
| DINOv3-B | 20 | 24 | 73% | [60, 84] | |
| Instance | RADIOv2.5-B | 19 | 27 | 77% | [64, 87] |
| DIFT₂ | 21 | 27 | 80% | [68, 89] | |
| Tracking | RADIOv2.5-B | 20 | 24 | 73% | [60, 84] |
| DIFT₂ | 23 | 26 | 82% | [70, 90] | |
| DIFT₈ | 21 | 27 | 80% | [68, 89] |
RQ4: How should keypoints be encoded in the policy? ▼
We compare four options for encoding the keypoints before passing them to the diffusion action head on Place Shoe and Place Mug. Our transformer encoder matches the no-encoder baseline (85%). We also try adding the similarity scores from the keypoint matching, but find this to performancy very poorly when combined with augmentations, pressumably due to overfitting on the similarity scores. We therefore do not recommend using similarity scores to encode the keypoints.
| Encoder | Avg. (%) | 95% CI |
|---|---|---|
| None (concatenation) | 85% | [73, 93] |
| Ours | 85% | [73, 93] |
| Ours + similarity scores | 7% | [2, 16] |
| Ours + similarity scores - augmentation | 65% | [52, 77] |
RQ5: Can KIL handle tasks with multiple object instances? ▼
We extend KIL to tasks involving two instances of the same object category. We refer to the paper for details on the changes made to the model and pipeline. We test on two tasks: placing two shoes and picking two pens, comparing against RGB and S²-Diffusion baselines. KIL performs on par with S²-Diffusion, and outperforms RGB, similar to the single-object tasks in RQ1.
| Method | Place 2 Shoes (/30) | Pick 2 Pens (/30) | Avg. (%) | 95% CI |
|---|---|---|---|---|
| RGB | 13 | 15.5 | 48% | [37, 58] |
| S²-Diffusion | 14.5 | 20.5 | 58% | [47, 69] |
| KIL (IM) | 21.5 | 16.5 | 63% | [54, 73] |
| KIL (IN) | 21.5 | 15 | 61% | [50, 72] |
| KIL (T) | 15.5 | 15.5 | 52% | [40, 63] |
Robustness Against Rotations ▼
We test sensitivity to initial object orientation by comparing performance under ±30° (default used in all other experiments) vs ±180° object rotation ranges on Place Mouse and Pick Pen. KIL is not rotation-robust: image matching drops 55 percentage points under large rotations (77% → 35%), compared to just 10 pp for RGB. This is a fundamental limitation inherited from the visual foundation models used for keypoint extraction, which fail to establish reliable correspondences when objects are significantly rotated.
| Method | ±180° orientations | ±30° orientations | Δ (30°→180°) | |
|---|---|---|---|---|
| Avg. (no scene var.) | Avg. | Avg. | ||
| RGB | 70% | 47% | 52% | −10% |
| S²-Diffusion | 80% | 70% | 77% | −9% |
| KIL (IM) | 45% | 35% | 77% | −55% |
| KIL (T) | 48% | 48% | 67% | −28% |